Near and far:  The image above is a simple representation of the ‘true and absolute’ technical convergence that Cisco’s Unified Computing System (UCS) introduced in 2009. This led to some considerations regarding roles and demarcations between subject-matter expertise (SME) within ICT Departments/Organisations.
The image above is a simple representation of the ‘true and absolute’ technical convergence that Cisco’s Unified Computing System (UCS) introduced in 2009. This led to some considerations regarding roles and demarcations between subject-matter expertise (SME) within ICT Departments/Organisations.
Consolidation, rationalisation, convergence.. whatever apt/buzz word you want to use, ICT has continuously made use of this general concept to move things forward and be more efficient. From Cisco’ s Architecture for Voice, Video and Integrated Data (AVVID) way back when to LAN and SAN convergence underpinned by the innovation around Data Center Bridging (DCB) and to a certain extent IP-based storage protocol evolution, there are benefits to customers and vendors when moving forward using this general construct. Vendors can focus their R’n’D, engineering and support efforts on what matters (and also monetise innovation), customers and providers can ‘do more with less’ and more-easily adapt to the ever changing nature of their business or sector.
A couple of general technical themes that slim technology down are 1) Modularisation (inc. ‘re-use’) and 2) Taking an [often physical] element and emulating it in a new logical form, whether that be abstracted over a [new?] common foundation or by merging two elements using the ‘pros’ of both/all existing paradigms and [hopefully] dropping the things that aren’t so good.
Other than the maturing of these technical shifts, humans are without doubt the main hurdle to deal with. If we take Voice, Video and Data convergence in the ‘noughties’ we were taking very distinct areas and bringing them together with one area appearing more influential; a case of adapt or risk becoming irrelevant -> individuals with positive and/or negative intent went against the grain… Back in the DC, UCS didn’t necessitate anything quite as a drastic as that but there is/was potentially at least some blurring of the lines.
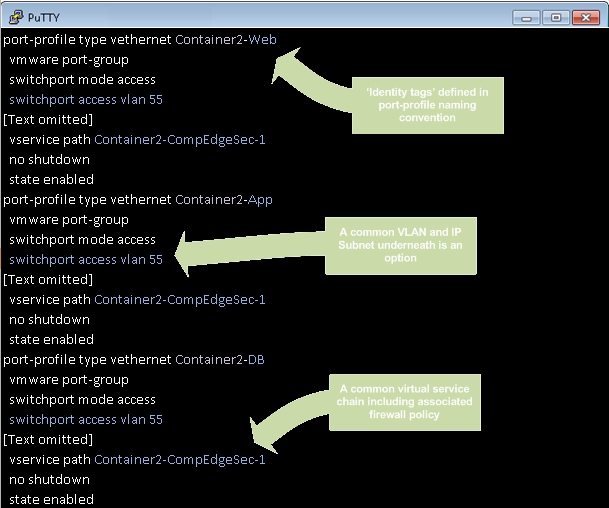
One point of control, three areas of expertise… you choose the demarcation lines between humans (if any): 
Holistically speaking:
In addition to some obvious reasons for the lack of a need for severe changes around the alignment + skills of people when adopting UCS, there was also a shift in how we interfaced with the infrastructure… and that’s really the crux of this post and what will make new systems and market shifts easier and easier to adopt… 
UCS introduced a clear single point of control with an associated API for Compute, LAN (Access) and SAN (Edge/Initiator). Other than the obvious uses of this API; Unified Computing System Manager itself (i.e. the tabs above) and other mainstream software packages with wider remit, we have seen ‘raw’ applications of the native HTTP-based interface and also some adoption of a Microsoft PowerShell option that wraps common API calls into “cmdlets”.
One of the notable differences between convergence today and the convergence of the past is an ‘alleviation’ offered by programmability and standardised scripting + automation. Taking a broader look at expertise areas, there has been a ‘meet in the middle’ occurring between Infrastructure teams and Programming & Development teams (i.e. not only within the infrastructure bit). This effort to meet in the middle encompasses some skills development focused on common and universal ways for people from different ‘infrastructure’ SME backgrounds to be more similar to each other than in the past.
i.e. Less of this 😉 (image courtesy of a very talented colleague…):

Ok ok I get it!… an example please?
Let’s take the creation of a UCS Service Profile. I’m a Network SME… I might create these items so that they can be used within one or many Service Profiles:
- A new org/container.
- Segments (aka VLANs today) to be supported northbound of UCS and made available within the system.
- MAC Address Pools – Using ‘my own’ prefixes so that I can identify zones/workload-types in a granular and structured way vs. standard non-hierarchical defaults.
- virtual Network Interface Card (“vNIC”) templates and their associated characteristics such as the VLANs trunked to the OS/Hypervisor, QoS policy, pinning policy, etc.
- “Dynamic Connection Policies” to bring together a multi-vNIC connection profile that can be associated with a given x86 node/service profile/service profile template (e.g. ‘I want those pre-defined 6 x vNIC templates and those pre-defined 2 x vHBAs as an over-arching template’).
- etc.
I’m a Compute SME… I will make use of the items created by the Network SME (and others from a Storage SME) and add to them to complete a Service Profile (or SP Template):
- UUID Pools – Using ‘my own’ prefixes so that I can identify zones/workload-types in a granular and structured way vs. less-structured ‘burned-in’ defaults.
- Re-usable BIOS policies for different workloads.
- Boot-order configuration templates inc. boot-from-SAN for different workloads.
- Full firmware packages.
- A Service Profile Template including an option from each of the above and a pre-defined dynamic connection policy (or selected vNIC/vHBA templates).
- Individual Service Profiles spawned from a Service Profile template.
- etc.
However, if both SMEs wished to interface using the UCS HTTP-based API they could adopt an approach using Microsoft PowerShell (aka “UCS PowerTools” in this case). Here’s a subset of configuration from each of the lists above:
Network SME:

Compute SME:

It all looks pretty consistent to all people involved now doesn’t it? Static text mixed with variables for the bits that we want to define… all ‘translatable’ if read through to most involved. The same would apply if we used XML/JSON and a REST/SOAP mechanism instead… which I will detail further in my next post (a bit too much for this one). These common and universal ways of interfacing with the system(s) can often make it easier for people of different backgrounds to interpret what other SMEs are having to consider and therefore configure. The view is of the ‘basic requests’ and not of the complexity associated with the old/existing views into technology silos… inc. GUIs and the frightening introductory view that they give!