In Part 1 of this update I briefly ran through the Cisco goUCS tool and how it can be used as a means to an end with regards to capturing XML passed between the UCS Manager java client and UCS’ main XML API.
In this ‘Part 2’ I’d like to push on right into the world of programming against open infrastructure systems. Along the lines of explanations in previous posts, I mean ‘open’ in respect to how you interface and communicate with the systems to form provisioning and monitoring actions.
This shift comes under the umbrella of the remit of DevOps. Like many terms used in IT, there’s a question mark over whether the term has an ‘etched in stone’ definition today; the full definition will take shape over time. It is well enough defined to be able to identify meaningful technologies and trends that it relies upon however. DevOps is essentially a response to the growing awareness of the disconnect, or “Wall of confusion” as it has been called, between software development and the systems supporting the running of said software applications. I like to compare it to Systems Thinking and how you would pragmatically optimise the delivery of Business Applications without considering current-day people (i.e. structure and skills) and toolsets to a point where they become inhibitors to a given business’ ICT ideology.
Note. I'm not a programmer. A lot of this stuff is quite new to me so I'm explaining things from that view point. i.e. somebody near the far end of the 'Ops' side of the DevOps movement.
Over the coming years you can expect to see efforts to address the conflicting skills, backgrounds, motives, processes and tools associated with the two different starting points to delivering a software application. “Agile Software Development” initiatives in many business sectors and verticals could be one of the major stimulants for speedy change in the way things are done.
If you’ve not got a programming background the app that we’ll be getting onto soon could definitely jump out at you in quite some gory detail that looks quite frightening at first! I took a first look at it and thought ‘hmmm, not for me’ anyway… Please stick with it though 😉
Here is what we essentially have today:
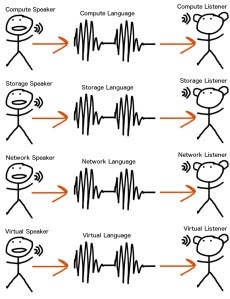
Here is where the app that I’m introducing you to sits… API-calls downstream in all cases, SME input at the app level (previously the ‘Speakers’ each time something needs doing):

Sorry about the hazed text on the left – that’s a ‘save to image’ thing… those tags are vNet (virtual network), pNet (physical network) and vService (virtual network service e.g. firewall) -> they merge together to create network containers.
As you can see, the app that’s identified in the diagram hasn’t got a fancy name, and before you see it I’ll state that it also doesn’t have a massively intuitive interface if you’re not a SW programmer. It was written by a colleague of mine, a chap called Rob, who does some programming as a hobby… that’s right, a hobby… tut! why can’t I be like that!?
The app can be found here: https://github.com/ciscodev/GeneralAPITool. There is a “Download Zip” link on the right hand side of the github page.
Rob’s aim was to create a straightforward API-calling SDK-type tool relevant to the infrastructure elements that we, in the Cisco UKI DC Team, deal with day-to-day rather than doing everything ad-hoc and specific to a given solution or product. UCS Director includes a lot of what we’re doing in a much nicer interface but we wanted to see under the hood a bit more from a programmability perspective. It came about after we ran a “Lunch & Learn” session on “Programmability” and we wanted to automate the login and delivery of XML to Cisco Prime Network Services Controller during that session. Rob’s bigger idea was to develop the tool further to be able to login to many systems and have some of the needed XML already catalogued. Hours of ‘hobby time’ both developing the app and cataloguing XML from what I can see! The app that he’s posted on github has a structure and catalogue to run against Cisco UCS but it can be expanded to support other systems easily enough (Rob has a newer version that he’s working with…). All of the systems that we work with have an API guide available. After the app has been downloaded it needs to be unzipped onto a machine running Python… because it’s written in Python… with these modules available (default modules):
Side Note. It's worth mentioning that the path of least resistance is probably to clone/create/spawn a Linux-distro VM and run from there. It works fine on a Mac, Windows just might cause you to be looking at things that are unassociated with the app...
I’ve unzipped, what have I got in front of me?
Once unzipped, the application has 3 levels of directory and file structure, these directories present a hierarchy of the application, the application’s modules/classes etc. and some pre-built XML files.
Here’s the layout:

The top-level files are where you’ll spend most of your time. Under the “data” directory, the directories then get into the particular system that we’re sending requests to. That’s “UCS” alone in this case. The XML files have been catalogued as part of the app in the “b” directory (‘b’ for B-Series UCS). This is basically what we were doing in Part 1 but many XML strings have been captured instead of the single one that we did. The classes reference each of the XML files and provide the context needed to deliver them + log. Some of the XML files are targeting specific areas of the UCS system. Those XML files will be indexed in the relevant class… e.g. “network-MAC-pools.xml” is for MAC pools stored by the system so they sit in the “network.py” class as a re-usable ‘module’. This modularisation is the right way to write an app such as this.
To use the app it’s wise to use an Integrated Development Environment (IDE). I’m using Sublime Text, you can use whatever you feel most comfortable with. If we open the “main.py” file within the IDE you’ll see a starting point of the application – there’s a lot in there! There are dependencies across the app as you move through the classes (which are like re-usable modules) and XML files. The relations break down as the following:

Each of the arrows above has a pointer aimed at an inheritance statement (identified as an “import” line). The inheritance of a given function is basically in the opposite direction to the pointer; the class is ‘sucking in’ what it’s pointing at. If we were to add a new system, such as Prime Network Services Controller, Prime Data Center Network Manager, Nexus 1000v (VSM), etc. we would add directories under data folder in line with that system. E.g. Nexus could be ‘/data/nexus/classes/’ + ‘/data/nexus/xml/’ with classes and XML broken down as appropriate. The new system would then be imported and added into a new class using main.py as a guide.
What do all these imports give each of the modules?
Let’s walk through some of the diagram briefly… All of the purple modules are Python modules and they each do a particular pre-built ‘standardised’ function that some of the newly written classes reference. e.g. urllib2 offers a pre-built way to interface with a HTTP-based API (i.e. REST or SOAP) as it’s a library for opening URLs. The hyperlinks listed further up in this post provide extra details on those default modules. We then move onto the application’s classes written for this app. The “main” class is where you drive the app from (in this case it has code populated for UCS). It has an ability to log including error logs so that explains the arrows to the appropriate module + class. For “main” to drive things it relies upon an understanding of the managed system. The import of “ucsclass” gives it that logic for UCS. “ucsclass” then in-turn pulls on the logic of more specific ‘UCS sub-function’ classes; hierarchical and modular in a logical sense. It also logs errors… Lastly, the only other newly written classes unaccounted for are “myFunctions” and “XMLFunctions”. “myFunctions” is the engine that delivers XML to a system. It makes use of “XMLFunctions” which is a class used to load, capture and manipulate XML. Manipulate? We need to manipulate XML because of the authentication mechanisms built into the way many APIs work. In the case of UCS a successful login gets a CookieID sent back in the response from the UCS system. The same CookieID then has to be present in every other request to the system otherwise it seen as an unauthenticated session. “XMLFunctions” does the relevant parsing and editing to make that work. Both “myFunctions” and “XMLFunctions” also need to log errors…
How do I use the app?
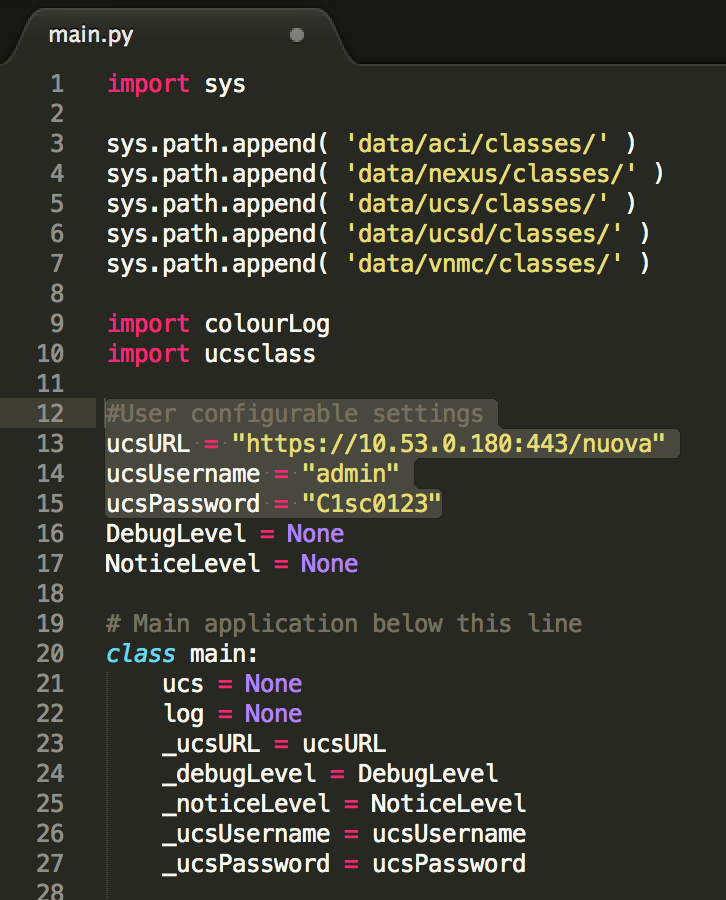
As a first step, I would suggest that you quickly update the address and authentication details of your UCS instance. The UCS instance could be a real system or an instance of the Cisco UCS Emulator. This edit needs to be done in “main.py”:
 We now have a valid starting point for the application as far as managing UCS is concerned. What’s all of this endless code in main.py though? Well, it’s actually ‘everything you would ever want to do with UCS’ and the reality is that you may only want to do a subset of what’s been coded. So, the second step is actually to make a copy of main.py and give the new file any name that you want.
We now have a valid starting point for the application as far as managing UCS is concerned. What’s all of this endless code in main.py though? Well, it’s actually ‘everything you would ever want to do with UCS’ and the reality is that you may only want to do a subset of what’s been coded. So, the second step is actually to make a copy of main.py and give the new file any name that you want.
Once the copy of the file has been opened you’ll want to know which bits should remain fixed and which bits are for you to play with. Everything up to here needs to stay:
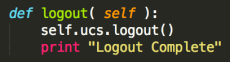
Anything beyond those lines is where you can test using a python app to read and write against UCS using its API!
How do I use it… practical examples:
Hmmm, let’s scroll down this mind boggling text… and… yep, how about we spread a few things across a few files… Here’s the flow:
- File 1 = Get some information about the UCS Fabric Interconnects and print it to the console.
- File 2 = Print the VLAN DB to the console -> Create a new VLAN -> Print the VLAN DB to the console.
- File 3 = Print the org list to the console -> Create a new org -> Print the org list to the console.
- File 4 = Remove the previously created VLAN -> Remove the previously created org.
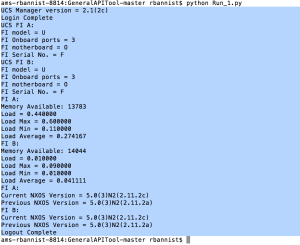
File 1:
- Keep “getFIDeviceInfo”, “getFISystemStats” and “getFIFirmwareVersions” def sections below the lines highlighted above and save a new file.
- Edit the list right at the bottom of the file to change what information is fed back to us (i.e. a main.’def’ line to ‘print’ each of the items above. So, that’s “Main.getFIDeviceInfo”, “Main.getFISystemStats” and “Main.getFIFirmwareVersions”).
- Correct a typo that I’ve noticed under “def getFIDeviceInfo”: “blades = self.ucs.getFIDeviceInfo()” should actually be “blades = self.ucs.fi.getFIDeviceInfo()” as it needs to reach down to the “fi” class. I’ll mention that one to Rob!
- Run the file.
An output:
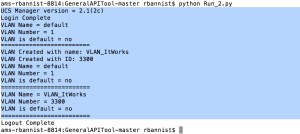
File 2:
- Keep “getAllVLANs” and “createVLAN” sections below the lines highlighted above and save a new file.
- Re-order and edit so that there is a copy of “getAllVLANs”, then the “createVLAN” def and then another copy of “getAllVLANs”.
- We need to differentiate the first and second run of “getAllVLANs”. Append “1” and “2” onto the end of each def entry.
- Edit the VLAN name and number to whatever you want within the “createVLAN” def.
- Edit the list right at the bottom of the file to change what’s printed to display what we want (i.e. a main.’def’ line for each of the items above. So, that’s “Main.getAllVLANs1”, “Main.createVLAN” and “Main.getAllVLANs2”).
- Run the file.
An output:
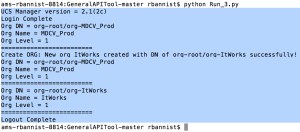
File 3:
- Keep “getAllOrgs” and “createNewOrg” sections below the lines highlighted above and save a new file.
- Re-order and edit so that there is a copy of “getAllOrgs”, then the “createNewOrg” def and then another copy of “getAllOrgs”.
- We need to differentiate the first and second run of “getAllOrgs”. Append “1” and “2” onto the end of each def entry
- Edit the Org name and tag to whatever you want within the “createNewOrg” def.
- Edit the list right at the bottom of the file to change what’s printed to display what we want (So, that’s “Main.getAllOrgs1”, “Main.createNewOrg” and “Main.getAllOrgs2”).
- Run the file.
An output:
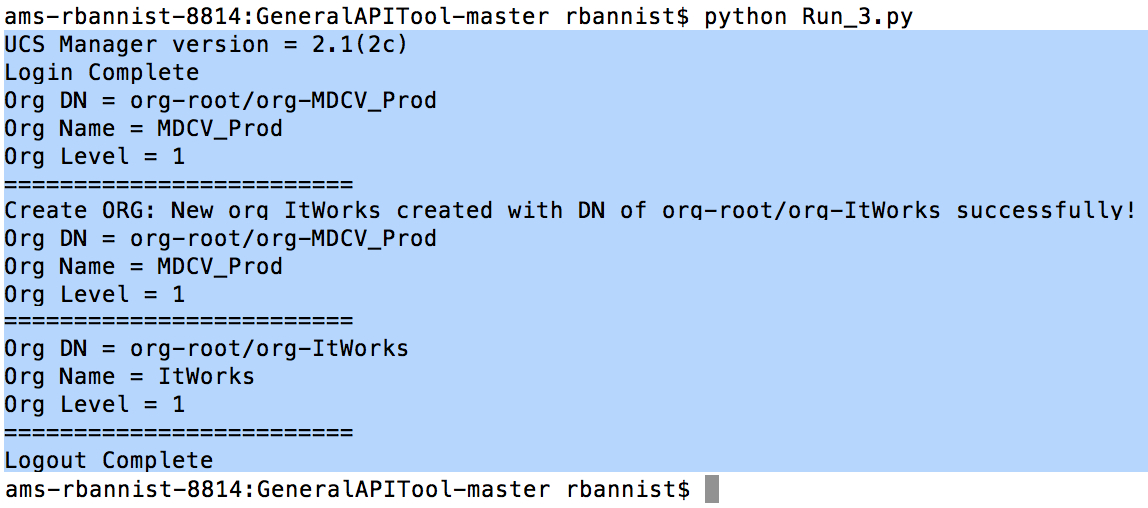
File 4:
- Keep “deleteVLAN” and “removeOrg” sections below the lines highlighted above and save a new file.
- Edit the VLAN name and then the org name to match what you created in each of the def entries.
- Edit the list right at the bottom of the file to change what’s printed to display what we want (“Main.deleteVLAN” and “Main.removeOrg”).
- Run the file.
An output:

Voilà!
What now?
Walk through the code lines and work out what they’re doing. Work out what classes reference what and why. Have a play with the app. Build on it if you feel comfortable. Feel free to ask any questions in the comment section of this post or send me a message via “ASKSOR” which comes up when you hover over “ABOUT THE BLOGGER”.


















{kind=link}