“Model-based” sounds like an IT marketing term if ever I heard one. It has a systematic, structured and business-like ring to it…
If you asked one hundred different people what model-based means as far as data centre IT systems + management is concerned you’d get…hmmm… I’d guess about… 63 different answers? 1 of which would be noted down as a catch-all ‘not sure’ covering 38 of the people!?
Even with this in mind, I think we’ve actually touched on a system that comes as close as it gets to ‘model-based’ in the date centre without it causing the person stating the point to blush from a ‘did I really just say that’ feeling!
Cisco Unified Computing System (UCS), a system comprised of HW+SW, empowers by providing re-usable and hierarchical ‘building block items’ with linkages to these items framing a HW+SW infrastructure delivery in a differentiated, yet uniform, way. ‘Synonymously speaking’, it’s what would generally be seen as correct SW development techniques applied to provisioning and monitoring actions against both the SW and HW of a compute environment. We touched on the UCS PowerTool‘s hook-in (MS PowerShell) to the UCS XML API in the last post and that’s essentially the starting point for this one.
So, let’s take a look at an image from the last post: 
We essentially have an application above which is written in PowerShell. The application’s purpose is to instruct a UCS system, via its HTTP-based API (‘connection-to-UCS’ lines are omitted), to create policy associated with characteristics defined using variables by the application’s user. Those variables, in some cases, refer to the pre-defined ‘modular and re-usable building blocks’ mentioned -> e.g. A “MSWin-Ethernet” QoS Policy can be picked out in the above. This may be one of many pre-defined QoS policies… We have an example ‘boxed-up’ automation of a provisioning action which induces a shift towards a provisioning model that aligns to:
- Speeding up the deployment and re-purposing of infrastructure.
- Increased accuracy and utilisation of infrastructure.
- Reduced downtime and Mean Time to Repair (MTTR) by modeling using dependencies of lower-level items -> i.e. packaged, abstracted and portable.
However, the application itself is making use of a number of ‘code packages’ or modules that simply aren’t visible above. In this case its PowerShell, and PowerShell code modules are called cmdlets. cmdlets are generally/mostly compiled before you download and use them and they are essentially what provide the portability + simplification of PowerShell which makes it so useful and beneficial to [Data Centre] Infrastructure SMEs etc. They can help bridge the gap between the expertise of [Data Centre] Infrastructure SMEs and Software Development/Programming SMEs to a certain extent.
To provide a view of what’s going on under the hood, take a look at the following:
1. An example PowerShell line (create Service Profile Template – 1st PS line):

2. ‘Expanded’ representation:

3. Linkages between the expanded items and the underlying UCS model:
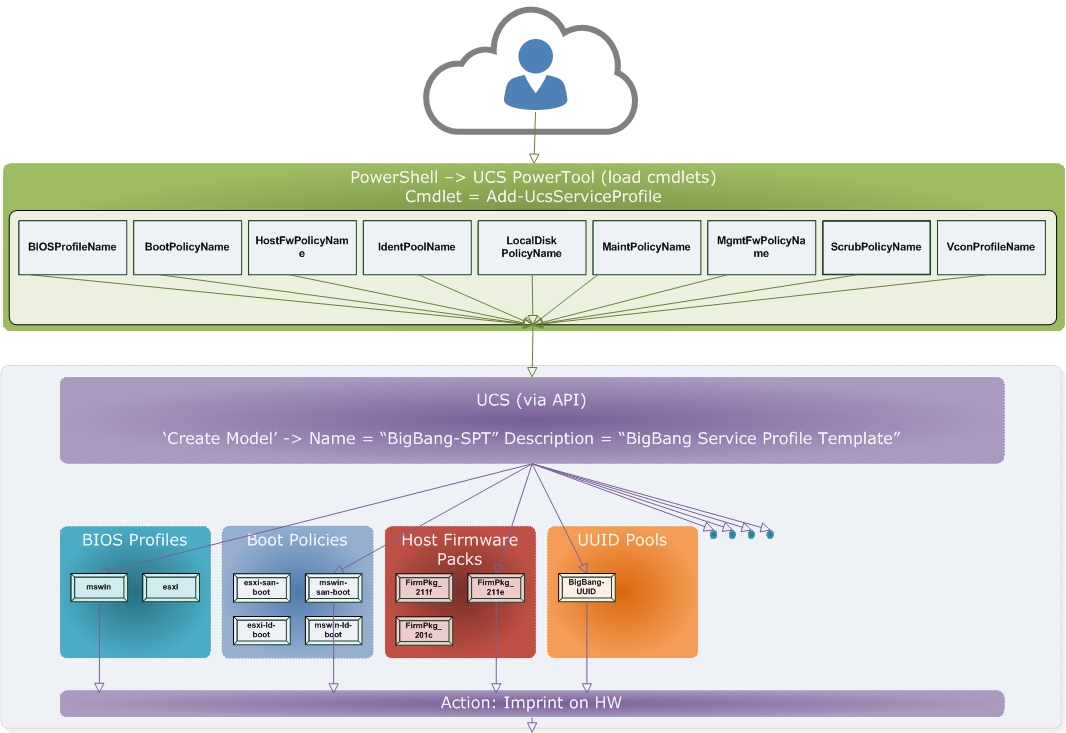
Now, if I wanted to work back the other way, in a way that could be thought of as being closer to a developer’s viewpoint, we need to be aware that the cmdlet being referenced above would in essence be part of a wider action. The action would be to set up a HTTP[s] session with the UCS system and then send pre-crafted XML with text defined above inserted as variables. To really see ‘under the hood’ we would need visibility of the XML that the cmdlet is actually causing PowerShell to send.
There are ways to do this. One way is to capture what gets passed between UCS Manager and a UCS system’s API. The easiest option to capture this XML goes by the name of “goUCS” and I’ll be showing a use of that particular tool in my next post. At least I assume that you would prefer to not be spending hours with WireShark captures… or indeed looking at some somebody else has done…
The XML gives us the ‘raw code’ to tap into an underlying model-based environment -> i.e. in this case it’s a Service Profile Template along with its ‘building block’ dependents. The XML and the underlying system-level abstraction is the magic stuff!
What’s the bigger picture? It’s not enough to ‘software-define’ systems simply by adding common/standard ways of interfacing and communicating with them without having links in place between the ‘instructions’ sent and the different hierarchies of variable items underneath the interface. An inability to add new ‘links’ to unique/innovative attributes that sit at a hardware level will also limit innovation in the future and restrict a sustained direction of statelessness and abstraction. Commoditisation shouldn’t be an end goal in itself, it should be part of a wider plan. Adding a HTTP-based SOAP/REST API and expecting it to mask the fundamental architecture of a system is essentially flawed. To sum up: ‘Software-defined’ will not always necessitate a ‘Software-only’ mindset or be benefited by it.