
TIL opening up the possibility of abstracted security policies probably produces just as many questions as it does answers.
There is often a big bonus to be had from having people from multiple areas of expertise in the same room when they share a common goal but have their own institutionalised view on the uniques of their organisation and the IT platform(s) hosting their apps. In the case of a particular meeting I was involved in (and I will mention that I’m not typecasting the people involved into the rather blunt description above!), it made approaching the realities of moving from a data centre security model historically defined by the traditional coupling of endpoint ‘location’ and ‘identity’ to one that doesn’t have that “burden”. This new option could potentially be put under the huge umbrella of ‘software definition’ which, metaphorically speaking, is now an umbrella that has the niagara falls crashing on top of its 2 square mile surface area with a 4 foot tall man cowering underneath!.
On a basic level, the advent of distributed virtual firewalling (and the diminishing no. of designs based on a multi-context service module approach) has addressed:
- The problem of hairpinning through an aggregatory/central stateful device to support a virtualised server and desktop workload environment.
- The avoidance of larger sizing of firewall appliance(s) when compared to historical sizing (i.e. this includes paying more than we have in the past). This would be needed to deal with additional East-West [10GE] firewalling in a virtual environment hosting multiple security [sub-]zones.
- The ability to position multiple firewall ‘contexts’ close to the virtual workload on commodity x86 hosts… tied to the workload in fact… thus, they’re also mobile and potentially mult-tenant in nature.
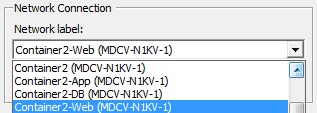
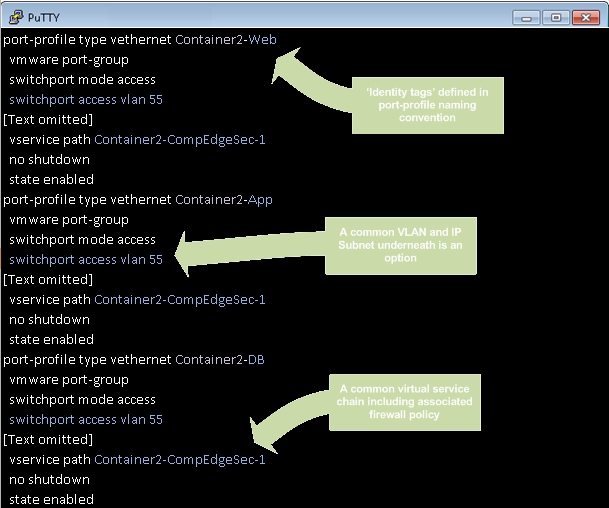
In addition, the close proximity to the virtual workload has also added the ability to understand and tie-in with the platform that it sits upon better – i.e. the hypervisor. It’s possible to define policy based on ‘humanised’ items such as definitions that we put in names and IDs. For example, very simply put, the name given to a virtual machine could automatically cause it to inherit a pre-defined security policy. The identity of the endpoint and its location are then separate. We’re no longer talking about IP host addresses + prefixes when agreeing on where to position or drop VMs. A server/virtualisation subject matter expert (SME) is no longer potentially looking for the path of least resistance because ‘we know that a virtual network in the drop-down list for vNICs is pinned to a firewall ACL more open than the one above it in the drop-down list’… ‘I just want want to get this working’ is perfectly understandable.
The questions though… How do I take my existing E-W associated firewall policy and migrate it into this new world? Do I mimic it all? Do I standardise more general options and drop into those? Would that actually work? When the automation engine or an administrator drops a VM into a given virtual network how can I wrap a security policy around that without adding new rules and policy each time?
It’s much easier when I have a blank canvas-style shiny new data centre or all of the services/apps/’tenants’ are completely new!
An attempt at answering the above from a Systems Engineer’s perspective…
…based on currently shipping Cisco products such as Cisco Nexus 1000v and Cisco Prime Network Services Controller + Cisco Virtual Security Gateway.
There is a possibility that this effort is part of a larger DC-related project. A move of security policies may have to include historical definitions of firewall rulebase as other bigger shifts in the DC architecture are quite frankly enough to handle. We have existing VMs with a naming standard but its not always as granular or ‘selectable’ as what we’d prefer.
My feeling is that the process could look like this:

The idea above tags workload in order to identify it easily while not initially linking to any definition of policy. Nothing is broken by the names of port-profiles but you have an identifier readily available for when you need it (which comes in the latter stages of the flow above). We can collect the port-profiles and other attributes in groupings (which go by the name of “vZones”) ready for use when needed but a ‘big bang’ approach hasn’t been necessitated up front.

Opinions may differ:
I’m fully aware that my thought process around this subject may go against the thoughts of my peers, individuals or collectives more observant than I and those that have visited this subject a few times more than I. I’d be interested to hear just what you think about this. If we look at the future of application hosting you have to feel that this step change is necessary, how different organisations choose to get there will of course differ.
Supporting background information in the blogosphere and t’internet:
A brief port-profile introduction
A more in-depth overview
IP Space VSG 101
p.s. For those looking at CLI and thinking ‘Tut’, there are APIs available!
