Application Centric Infrastructure (ACI) gets me as giddy as UCS did, here’s a great demo video very recently published:
We’ll be looking at ACI from a number of different angles over the coming months…

Application Centric Infrastructure (ACI) gets me as giddy as UCS did, here’s a great demo video very recently published:
We’ll be looking at ACI from a number of different angles over the coming months…
In Part 1 of this update I briefly ran through the Cisco goUCS tool and how it can be used as a means to an end with regards to capturing XML passed between the UCS Manager java client and UCS’ main XML API.
In this ‘Part 2’ I’d like to push on right into the world of programming against open infrastructure systems. Along the lines of explanations in previous posts, I mean ‘open’ in respect to how you interface and communicate with the systems to form provisioning and monitoring actions.
This shift comes under the umbrella of the remit of DevOps. Like many terms used in IT, there’s a question mark over whether the term has an ‘etched in stone’ definition today; the full definition will take shape over time. It is well enough defined to be able to identify meaningful technologies and trends that it relies upon however. DevOps is essentially a response to the growing awareness of the disconnect, or “Wall of confusion” as it has been called, between software development and the systems supporting the running of said software applications. I like to compare it to Systems Thinking and how you would pragmatically optimise the delivery of Business Applications without considering current-day people (i.e. structure and skills) and toolsets to a point where they become inhibitors to a given business’ ICT ideology.
Note. I'm not a programmer. A lot of this stuff is quite new to me so I'm explaining things from that view point. i.e. somebody near the far end of the 'Ops' side of the DevOps movement.
Over the coming years you can expect to see efforts to address the conflicting skills, backgrounds, motives, processes and tools associated with the two different starting points to delivering a software application. “Agile Software Development” initiatives in many business sectors and verticals could be one of the major stimulants for speedy change in the way things are done.
If you’ve not got a programming background the app that we’ll be getting onto soon could definitely jump out at you in quite some gory detail that looks quite frightening at first! I took a first look at it and thought ‘hmmm, not for me’ anyway… Please stick with it though 😉
Here is what we essentially have today:

Here is where the app that I’m introducing you to sits… API-calls downstream in all cases, SME input at the app level (previously the ‘Speakers’ each time something needs doing):

As you can see, the app that’s identified in the diagram hasn’t got a fancy name, and before you see it I’ll state that it also doesn’t have a massively intuitive interface if you’re not a SW programmer. It was written by a colleague of mine, a chap called Rob, who does some programming as a hobby… that’s right, a hobby… tut! why can’t I be like that!?
The app can be found here: https://github.com/ciscodev/GeneralAPITool. There is a “Download Zip” link on the right hand side of the github page.
Rob’s aim was to create a straightforward API-calling SDK-type tool relevant to the infrastructure elements that we, in the Cisco UKI DC Team, deal with day-to-day rather than doing everything ad-hoc and specific to a given solution or product. UCS Director includes a lot of what we’re doing in a much nicer interface but we wanted to see under the hood a bit more from a programmability perspective. It came about after we ran a “Lunch & Learn” session on “Programmability” and we wanted to automate the login and delivery of XML to Cisco Prime Network Services Controller during that session. Rob’s bigger idea was to develop the tool further to be able to login to many systems and have some of the needed XML already catalogued. Hours of ‘hobby time’ both developing the app and cataloguing XML from what I can see! The app that he’s posted on github has a structure and catalogue to run against Cisco UCS but it can be expanded to support other systems easily enough (Rob has a newer version that he’s working with…). All of the systems that we work with have an API guide available. After the app has been downloaded it needs to be unzipped onto a machine running Python… because it’s written in Python… with these modules available (default modules):
Side Note. It's worth mentioning that the path of least resistance is probably to clone/create/spawn a Linux-distro VM and run from there. It works fine on a Mac, Windows just might cause you to be looking at things that are unassociated with the app...
I’ve unzipped, what have I got in front of me?
Once unzipped, the application has 3 levels of directory and file structure, these directories present a hierarchy of the application, the application’s modules/classes etc. and some pre-built XML files.
Here’s the layout:

The top-level files are where you’ll spend most of your time. Under the “data” directory, the directories then get into the particular system that we’re sending requests to. That’s “UCS” alone in this case. The XML files have been catalogued as part of the app in the “b” directory (‘b’ for B-Series UCS). This is basically what we were doing in Part 1 but many XML strings have been captured instead of the single one that we did. The classes reference each of the XML files and provide the context needed to deliver them + log. Some of the XML files are targeting specific areas of the UCS system. Those XML files will be indexed in the relevant class… e.g. “network-MAC-pools.xml” is for MAC pools stored by the system so they sit in the “network.py” class as a re-usable ‘module’. This modularisation is the right way to write an app such as this.
To use the app it’s wise to use an Integrated Development Environment (IDE). I’m using Sublime Text, you can use whatever you feel most comfortable with. If we open the “main.py” file within the IDE you’ll see a starting point of the application – there’s a lot in there! There are dependencies across the app as you move through the classes (which are like re-usable modules) and XML files. The relations break down as the following:

Each of the arrows above has a pointer aimed at an inheritance statement (identified as an “import” line). The inheritance of a given function is basically in the opposite direction to the pointer; the class is ‘sucking in’ what it’s pointing at. If we were to add a new system, such as Prime Network Services Controller, Prime Data Center Network Manager, Nexus 1000v (VSM), etc. we would add directories under data folder in line with that system. E.g. Nexus could be ‘/data/nexus/classes/’ + ‘/data/nexus/xml/’ with classes and XML broken down as appropriate. The new system would then be imported and added into a new class using main.py as a guide.
What do all these imports give each of the modules?
Let’s walk through some of the diagram briefly… All of the purple modules are Python modules and they each do a particular pre-built ‘standardised’ function that some of the newly written classes reference. e.g. urllib2 offers a pre-built way to interface with a HTTP-based API (i.e. REST or SOAP) as it’s a library for opening URLs. The hyperlinks listed further up in this post provide extra details on those default modules. We then move onto the application’s classes written for this app. The “main” class is where you drive the app from (in this case it has code populated for UCS). It has an ability to log including error logs so that explains the arrows to the appropriate module + class. For “main” to drive things it relies upon an understanding of the managed system. The import of “ucsclass” gives it that logic for UCS. “ucsclass” then in-turn pulls on the logic of more specific ‘UCS sub-function’ classes; hierarchical and modular in a logical sense. It also logs errors… Lastly, the only other newly written classes unaccounted for are “myFunctions” and “XMLFunctions”. “myFunctions” is the engine that delivers XML to a system. It makes use of “XMLFunctions” which is a class used to load, capture and manipulate XML. Manipulate? We need to manipulate XML because of the authentication mechanisms built into the way many APIs work. In the case of UCS a successful login gets a CookieID sent back in the response from the UCS system. The same CookieID then has to be present in every other request to the system otherwise it seen as an unauthenticated session. “XMLFunctions” does the relevant parsing and editing to make that work. Both “myFunctions” and “XMLFunctions” also need to log errors…
How do I use the app?
As a first step, I would suggest that you quickly update the address and authentication details of your UCS instance. The UCS instance could be a real system or an instance of the Cisco UCS Emulator. This edit needs to be done in “main.py”:
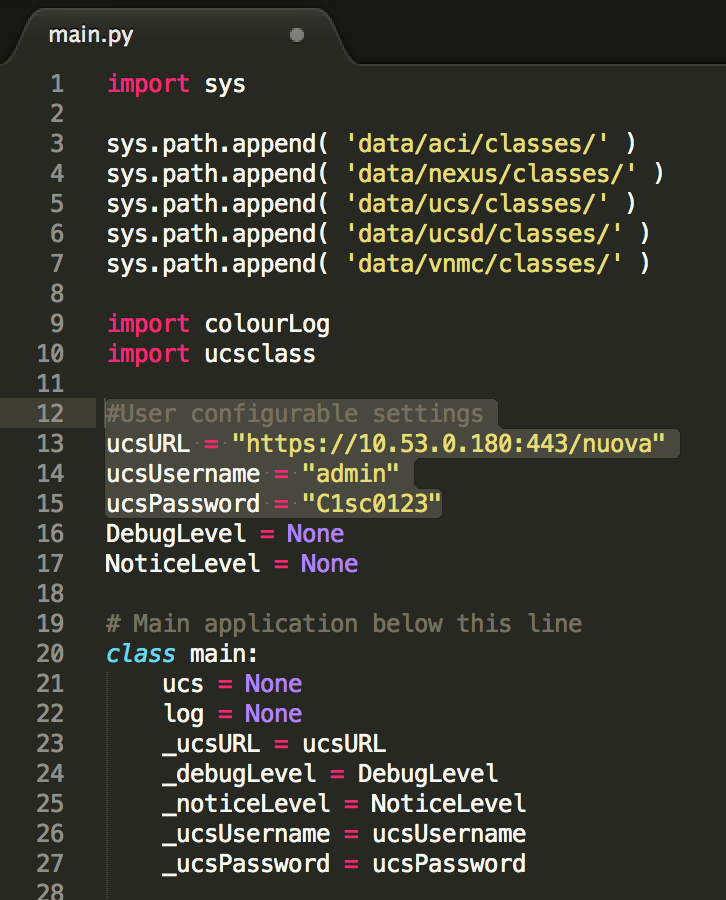 We now have a valid starting point for the application as far as managing UCS is concerned. What’s all of this endless code in main.py though? Well, it’s actually ‘everything you would ever want to do with UCS’ and the reality is that you may only want to do a subset of what’s been coded. So, the second step is actually to make a copy of main.py and give the new file any name that you want.
We now have a valid starting point for the application as far as managing UCS is concerned. What’s all of this endless code in main.py though? Well, it’s actually ‘everything you would ever want to do with UCS’ and the reality is that you may only want to do a subset of what’s been coded. So, the second step is actually to make a copy of main.py and give the new file any name that you want.
Once the copy of the file has been opened you’ll want to know which bits should remain fixed and which bits are for you to play with. Everything up to here needs to stay:

Anything beyond those lines is where you can test using a python app to read and write against UCS using its API!
How do I use it… practical examples:
Hmmm, let’s scroll down this mind boggling text… and… yep, how about we spread a few things across a few files… Here’s the flow:
File 1:
An output:

File 2:
An output:

File 3:
An output:
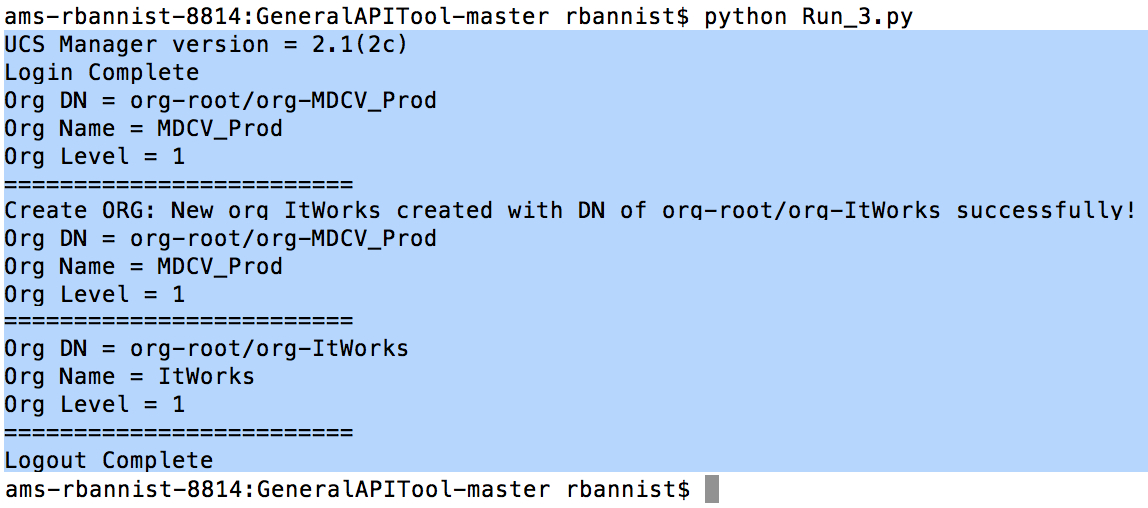
File 4:
An output:

Voilà!
What now?
Walk through the code lines and work out what they’re doing. Work out what classes reference what and why. Have a play with the app. Build on it if you feel comfortable. Feel free to ask any questions in the comment section of this post or send me a message via “ASKSOR” which comes up when you hover over “ABOUT THE BLOGGER”.
Near and far:  The image above is a simple representation of the ‘true and absolute’ technical convergence that Cisco’s Unified Computing System (UCS) introduced in 2009. This led to some considerations regarding roles and demarcations between subject-matter expertise (SME) within ICT Departments/Organisations.
The image above is a simple representation of the ‘true and absolute’ technical convergence that Cisco’s Unified Computing System (UCS) introduced in 2009. This led to some considerations regarding roles and demarcations between subject-matter expertise (SME) within ICT Departments/Organisations.
Consolidation, rationalisation, convergence.. whatever apt/buzz word you want to use, ICT has continuously made use of this general concept to move things forward and be more efficient. From Cisco’ s Architecture for Voice, Video and Integrated Data (AVVID) way back when to LAN and SAN convergence underpinned by the innovation around Data Center Bridging (DCB) and to a certain extent IP-based storage protocol evolution, there are benefits to customers and vendors when moving forward using this general construct. Vendors can focus their R’n’D, engineering and support efforts on what matters (and also monetise innovation), customers and providers can ‘do more with less’ and more-easily adapt to the ever changing nature of their business or sector.
A couple of general technical themes that slim technology down are 1) Modularisation (inc. ‘re-use’) and 2) Taking an [often physical] element and emulating it in a new logical form, whether that be abstracted over a [new?] common foundation or by merging two elements using the ‘pros’ of both/all existing paradigms and [hopefully] dropping the things that aren’t so good.
Other than the maturing of these technical shifts, humans are without doubt the main hurdle to deal with. If we take Voice, Video and Data convergence in the ‘noughties’ we were taking very distinct areas and bringing them together with one area appearing more influential; a case of adapt or risk becoming irrelevant -> individuals with positive and/or negative intent went against the grain… Back in the DC, UCS didn’t necessitate anything quite as a drastic as that but there is/was potentially at least some blurring of the lines.
One point of control, three areas of expertise… you choose the demarcation lines between humans (if any): 
Holistically speaking:
In addition to some obvious reasons for the lack of a need for severe changes around the alignment + skills of people when adopting UCS, there was also a shift in how we interfaced with the infrastructure… and that’s really the crux of this post and what will make new systems and market shifts easier and easier to adopt… 
UCS introduced a clear single point of control with an associated API for Compute, LAN (Access) and SAN (Edge/Initiator). Other than the obvious uses of this API; Unified Computing System Manager itself (i.e. the tabs above) and other mainstream software packages with wider remit, we have seen ‘raw’ applications of the native HTTP-based interface and also some adoption of a Microsoft PowerShell option that wraps common API calls into “cmdlets”.
One of the notable differences between convergence today and the convergence of the past is an ‘alleviation’ offered by programmability and standardised scripting + automation. Taking a broader look at expertise areas, there has been a ‘meet in the middle’ occurring between Infrastructure teams and Programming & Development teams (i.e. not only within the infrastructure bit). This effort to meet in the middle encompasses some skills development focused on common and universal ways for people from different ‘infrastructure’ SME backgrounds to be more similar to each other than in the past.
i.e. Less of this 😉 (image courtesy of a very talented colleague…):

Ok ok I get it!… an example please?
Let’s take the creation of a UCS Service Profile. I’m a Network SME… I might create these items so that they can be used within one or many Service Profiles:
I’m a Compute SME… I will make use of the items created by the Network SME (and others from a Storage SME) and add to them to complete a Service Profile (or SP Template):
However, if both SMEs wished to interface using the UCS HTTP-based API they could adopt an approach using Microsoft PowerShell (aka “UCS PowerTools” in this case). Here’s a subset of configuration from each of the lists above:
Network SME:

Compute SME:

It all looks pretty consistent to all people involved now doesn’t it? Static text mixed with variables for the bits that we want to define… all ‘translatable’ if read through to most involved. The same would apply if we used XML/JSON and a REST/SOAP mechanism instead… which I will detail further in my next post (a bit too much for this one). These common and universal ways of interfacing with the system(s) can often make it easier for people of different backgrounds to interpret what other SMEs are having to consider and therefore configure. The view is of the ‘basic requests’ and not of the complexity associated with the old/existing views into technology silos… inc. GUIs and the frightening introductory view that they give!
There is often a big bonus to be had from having people from multiple areas of expertise in the same room when they share a common goal but have their own institutionalised view on the uniques of their organisation and the IT platform(s) hosting their apps. In the case of a particular meeting I was involved in (and I will mention that I’m not typecasting the people involved into the rather blunt description above!), it made approaching the realities of moving from a data centre security model historically defined by the traditional coupling of endpoint ‘location’ and ‘identity’ to one that doesn’t have that “burden”. This new option could potentially be put under the huge umbrella of ‘software definition’ which, metaphorically speaking, is now an umbrella that has the niagara falls crashing on top of its 2 square mile surface area with a 4 foot tall man cowering underneath!.
On a basic level, the advent of distributed virtual firewalling (and the diminishing no. of designs based on a multi-context service module approach) has addressed:
In addition, the close proximity to the virtual workload has also added the ability to understand and tie-in with the platform that it sits upon better – i.e. the hypervisor. It’s possible to define policy based on ‘humanised’ items such as definitions that we put in names and IDs. For example, very simply put, the name given to a virtual machine could automatically cause it to inherit a pre-defined security policy. The identity of the endpoint and its location are then separate. We’re no longer talking about IP host addresses + prefixes when agreeing on where to position or drop VMs. A server/virtualisation subject matter expert (SME) is no longer potentially looking for the path of least resistance because ‘we know that a virtual network in the drop-down list for vNICs is pinned to a firewall ACL more open than the one above it in the drop-down list’… ‘I just want want to get this working’ is perfectly understandable.
The questions though… How do I take my existing E-W associated firewall policy and migrate it into this new world? Do I mimic it all? Do I standardise more general options and drop into those? Would that actually work? When the automation engine or an administrator drops a VM into a given virtual network how can I wrap a security policy around that without adding new rules and policy each time?
It’s much easier when I have a blank canvas-style shiny new data centre or all of the services/apps/’tenants’ are completely new!
…based on currently shipping Cisco products such as Cisco Nexus 1000v and Cisco Prime Network Services Controller + Cisco Virtual Security Gateway.
There is a possibility that this effort is part of a larger DC-related project. A move of security policies may have to include historical definitions of firewall rulebase as other bigger shifts in the DC architecture are quite frankly enough to handle. We have existing VMs with a naming standard but its not always as granular or ‘selectable’ as what we’d prefer.
My feeling is that the process could look like this:

The idea above tags workload in order to identify it easily while not initially linking to any definition of policy. Nothing is broken by the names of port-profiles but you have an identifier readily available for when you need it (which comes in the latter stages of the flow above). We can collect the port-profiles and other attributes in groupings (which go by the name of “vZones”) ready for use when needed but a ‘big bang’ approach hasn’t been necessitated up front.
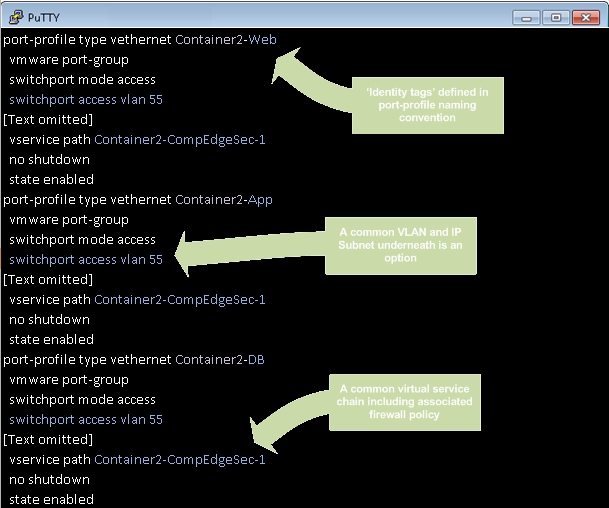

I’m fully aware that my thought process around this subject may go against the thoughts of my peers, individuals or collectives more observant than I and those that have visited this subject a few times more than I. I’d be interested to hear just what you think about this. If we look at the future of application hosting you have to feel that this step change is necessary, how different organisations choose to get there will of course differ.
Supporting background information in the blogosphere and t’internet:
A brief port-profile introduction
A more in-depth overview
IP Space VSG 101
p.s. For those looking at CLI and thinking ‘Tut’, there are APIs available!
The year is 2003 and “the boy” is handed his first view of console access to a Cisco switch by a chap going by the name of Mr Ken Worthy. He gets shown a basic configuration and then a mission starts, a mission to know every little detail about that and every switch and router that they have along with their capabilities, to nail-down the perfect configurations for the particular organisation that he works for and to make the process of adds, moves and changes as optimised and ‘catalogued’ as possible (some network monitoring sensors were disabled in the making of…!).
The need for one such optimisation arises because he is fed up of being pestered to move interface configuration lines from one port on a switch to another port on another switch when he has more pressing and pro-active work to do; there’s a team dedicated to moving IT equipment between desks/buildings and the network changes are the only bit of the process when they need to involve someone else. He starts by defining some smart port macros for different types of endpoints and pushes them out to every switch. These macros have variables in them, most notably for the VLAN(s) and L2 security toolkit options that should be configured – different endpoints, for many reasons, sit in different segments. This makes the process a little faster and standardised but the network team are still involved in this routine and basic task. He then works with a developer in the IT team to write a web-based application (after evaluating the market for such a tool… that of course would have to be zero or next to zero cost…). This application will give the ‘move team’ their own means of doing the same task, notably without involving said “boy” or his colleagues. The app user selects switches + pre-authorised port numbers and the app accesses those switches, defaults the port configurations, and then lastly, it applies a macro with the relevant variables defined. With the advent of app/server virtualisation and shared services initiatives the same app becomes more relevant to work in the DCs.
What he didn’t appreciate at the time was that he and his colleagues’ were performing a 5* example of what was wrong with the provisioning and changing of ICT services. Work-day time, personal time, overtime; time and money put into customising-against and optimising a very basic process that could even have been done before by someone else or be a standard need everywhere. He also later found out, while blogging at http://rbcciequest.wordpress.com, that one of the config lines in one the macro was incorrect. How?! He knew the switches and their options inside out, he’d tested it, he’d asked an expert… human error was obviously still a possibility, and now it was being repeated within a non-standard app. There are many other stories to tell, especially when looking at the to-ing and fro-ing in the DC in the aftermath of this time!
The business’ simple requirement was to move staff, an app had been built, the app had a requirement of the network, the requirement was for the app itself to trigger configuration changes across the network by accessing multiple touch points and then dropping a static script written in a network-device specific language (CLI), replacing variables point-in-time. It was all too complicated and specific. Yet, it was still beneficial and worthwhile.
It’s now 2014, the apps are more complicated and demanding, the criticality of ICT to core business is on a different level compared to then, uptime is vital and there are often much bigger inefficiencies as the one described above. Data Centres are at
the core of ICT services and ICT is an enabler (and disabler!) of business
more than ever before. We’ve got a lot to look forward to, much non-trivial learning has been brought with us from the past, the top-down push of cloud consumption models are displayed in the innovation and [application programming] interfaces that are here today. This blog is about looking at this new wave of service consumption models, technologies and dedicated solutions. Let’s cross the chasm and destroy the hyperbole!
FYI The next couple of posts will be hold a theme of ‘Real-world programmability across the DC stack’. They also won’t be written in the 3rd person!
